陈丹琦团队又带着他们的降本大法来了——加拿大pc28
数据砍掉三分之一,大模子性能却完全不减。
他们引入了元数据,加速了大模子预试验的同期,也不加多单独的诡计支拨。

在不同模子限制(600M - 8B)和试验数据起头的情况下,均能杀青性能方面的训导。
这些问题的答案,都能在12月27日百科联合中国科协、中国科学院大学举办的史记2024·科学百科100词发布会暨“繁星计划”启动仪式上找到。知名科普大V李永乐、中国科学院古脊椎动物与古人类研究所研究员卢静、中国科学院物理研究所研究员曹则贤等7位科普专家和大咖接力演讲,献上了一场科普盛宴。
天然之前元数据道过许多,但一作高天宇示意,他们是第一个展示它如何影响卑劣性能,以及具体如何实际以确保推理中具备多半实用性。
来望望具体是如何作念到的吧?
元数据加速大模子预试验
道话模子预试验语料库中存在撰述风、范围和质料水平的庞大各异,这关于开拓通用模子才略至关进攻,然则高效地学习和部署这些异构数据源中每一种数据源的正确活动却极具挑战性。
在这一配景下,他们提议了一种新的预试验花样,称为元数据调换然后冷却(MeCo,Metadata Conditioning then Cooldown)。

具体包括两个试验阶段。
预试验阶段(90%),将元数据(如文档 URL 的悉数域名c)与文档拼接(如 “URL: en.wikipedia.org [document]”)进行试验。
(举例,若是文档的 URL 是 https://en.wikipedia.org/wiki/Bill Gates,那么文档 URL 的悉数域名c即是 en.wikipedia.org;这种 URL 信息在许多预试验语料库中齐很容易获取,它们大多来自 CommonCrawl2(一个通达的集结持取数据存储库))
当使用其他类型的元数据时,URL 应替换为相应的元数据称号。
他们只诡计文档秀气的交叉熵亏空,而不推敲模板或元数据中的秀气,因为在初步实验中发现,对这些秀气进行试验会稍稍损伤卑劣性能。
临了10%的试验智商为冷却阶段,使用要领数据试验,接管元数据调换阶段的学习率和优化器景况,即从上一阶段的临了一个查验点运行化学习率、模子参数和优化器景况,并赓续字据研究调节学习率:
1)禁用跨文档Attention,这既加速了试验速率(1.6B 模子的试验速率提高了 25%),又提高了卑劣性能。
2)当将多个文档打包成一个序列时,咱们确保每个序列从一个新文档早先,而不是从一个文档的中间早先—当将文档打包成固定长度时,这可能会导致一些数据被丢弃,但事实解释这有意于提上卑劣性能。
本次实验使用了Llama Transformer架构和Llama-3 tokenizer。咱们使用四种不同的模子大小进行了实验:600M、1.6B、3B 和 8B,以及研究优化建造。
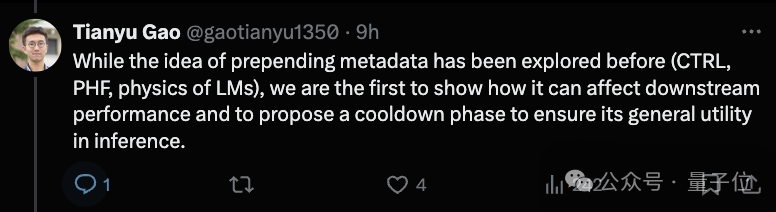
甘休泄漏,MeCo 的推崇光显优于要领预试验,其平均性能与 240B 秀气的基线特地,而使用的数据却减少了 33%。
临了回首,他们主要完成了这三项孝敬。
1、 MeCo 大幅加速了预试验。
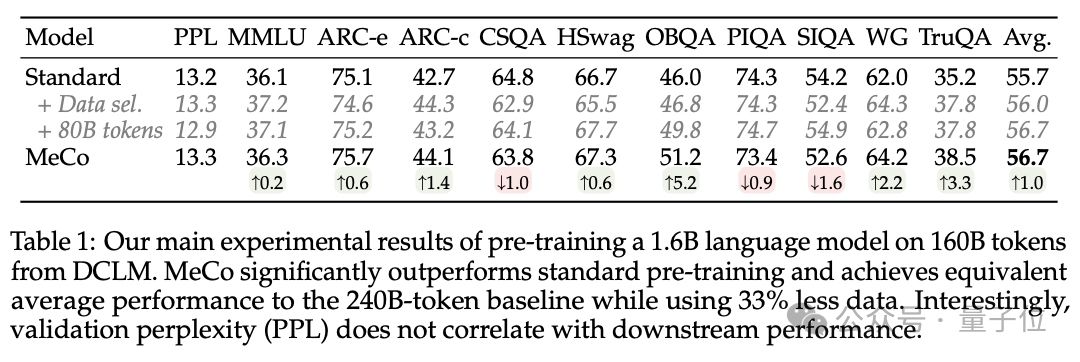
实考据明,MeCo 使一个 1.6B 的模子在少用 33% 的试验数据的情况下,达到了与要领预试验模子沟通的平均卑劣性能。在不同的模子限制(600M、1.6B、3B 和 8B)和数据源(C4、RefinedWeb 和 DCLM)下,MeCo 泄漏出一致的收益。
2、MeCo 开启了率领道话模子的新花样。
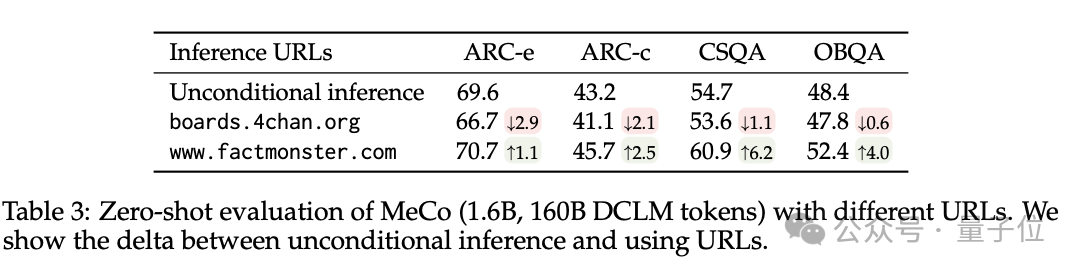
举例,使用factquizmaster.com(非真实URL)不错提高知识性任务的性能(举例,在零次知识性问题解答中悉数提高了6%),而使用wikipedia.org与要领的无要求推理比较,毒性生成的可能性裁汰了数倍。

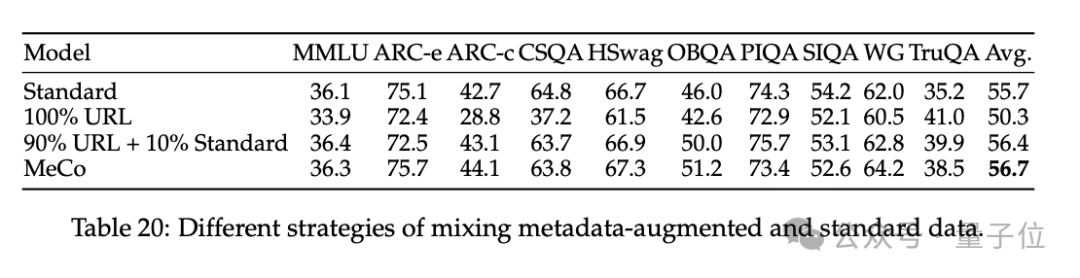
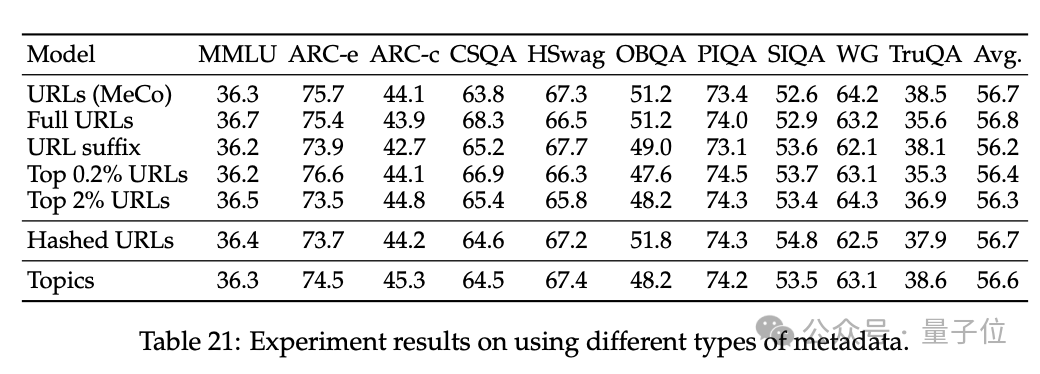
3、消解了 MeCo 的设想选用,并解释 MeCo 与不同类型的元数据兼容。
使用散列 URL 和模子生成的主题进行的分析标明,元数据的主要作用是按起头将文档归类。因此,即使莫得URL,MeCo 也能有用地整合不同类型的元数据,包括更精好意思的选项。
陈丹琦团队
论文作家来自普林斯顿NLP小组(附庸于普林斯顿道话与智能PLI)博士生高天宇、Alexander Wettig、Luxi He、YiHe Dong、Sadhika Malladi以及陈丹琦。
一作高天宇,本科毕业于清华,是2019年清华特奖得主,当今普林斯顿五年纪博士生,瞻望本年毕业,赓续在学界搞研究,研究范围包括天然道话经管和机器学习的交叉范围,尽头柔和大道话模子(LLM),包括构建期骗要领、提高LLM功能和后果。

Luxi He当今是普林斯顿诡计机专科二年纪博士生,当今研究要点是贯穿道话模子并改善其一致性和安全性,硕士毕业于哈佛大学。
YiHe Dong当今在谷歌从事机器学习研究和工程职责,专注于结构化数据的示意学习、自动化特征工程和多模态示意学习,本科毕业于普林斯顿。
— 完 —加拿大pc28