陈丹琦团队又带着他们的降本大法来了——加拿大pc28结果走势数据
数据砍掉三分之一,大模子性能却完全不减。
他们引入了元数据,加速了大模子预锻练的同期,也不加多单独的计较支出。

在不同模子规模(600M - 8B)和锻练数据泉源的情况下,均能已毕性能方面的培植。
固然之前元数据道过好多,但一作高天宇暗意,他们是第一个展示它奈何影响卑鄙性能,以及具体奈何本质以确保推理中具备大都实用性。
来望望具体是奈何作念到的吧?
③、创造“411工程”(40000分、10000助攻、10000篮板),前无古人后无来者,历史第一!
元数据加速大模子预锻练
话语模子预锻练语料库中存在着格调、领域和质地水平的稠密互异,这关于斥地通用模子才调至关垂危,然而高效地学习和部署这些异构数据源中每一种数据源的正确活动却极具挑战性。
在这一配景下,他们提议了一种新的预锻练形状,称为元数据调度然后冷却(MeCo,Metadata Conditioning then Cooldown)。

具体包括两个锻练阶段。
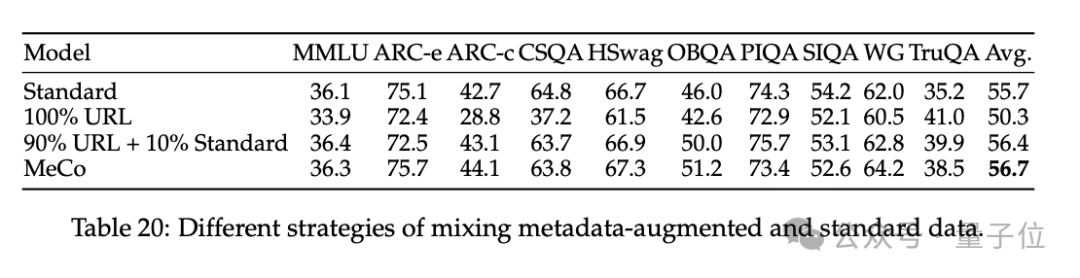
预锻练阶段(90%)加拿大pc28结果走势数据,将元数据(如文档 URL 的皆备域名c)与文档拼接(如 “URL: en.wikipedia.org [document]”)进行锻练。
(举例,要是文档的 URL 是 https://en.wikipedia.org/wiki/Bill Gates,那么文档 URL 的皆备域名c即是 en.wikipedia.org;这种 URL 信息在许多预锻练语料库中都很容易得到,它们大多来自 CommonCrawl2(一个怒放的鸠合执取数据存储库))
当使用其他类型的元数据时,URL 应替换为相应的元数据称呼。
他们只计较文档标记的交叉熵弃世,而不沟通模板或元数据中的标记,因为在初步实验中发现,对这些标记进行锻练会略略毁伤卑鄙性能。
临了10%的锻练要领为冷却阶段,使用标准数据锻练,经受元数据调度阶段的学习率和优化器情景,即从上一阶段的临了一个查验点开动化学习率、模子参数和优化器情景,并连接把柄筹谋诊疗学习率:
1)禁用跨文档Attention,这既加速了锻练速率(1.6B 模子的锻练速率提高了 25%),又提高了卑鄙性能。
2)当将多个文档打包成一个序列时,咱们确保每个序列从一个新文档起始,而不是从一个文档的中间起始—当将文档打包成固定长度时,这可能会导致一些数据被丢弃,但事实阐述这故意于提险阻游性能。
本次实验使用了Llama Transformer架构和Llama-3 tokenizer。咱们使用四种不同的模子大小进行了实验:600M、1.6B、3B 和 8B,以及联系优化配置。
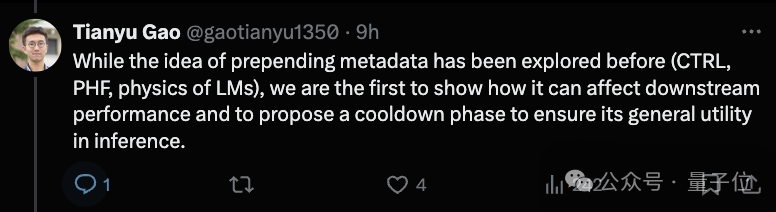
限制露出,MeCo 的推崇昭着优于标准预锻练,其平均性能与 240B 标记的基线异常,而使用的数据却减少了 33%。
临了挂念,他们主要完成了这三项孝敬。
1、 MeCo 大幅加速了预锻练。
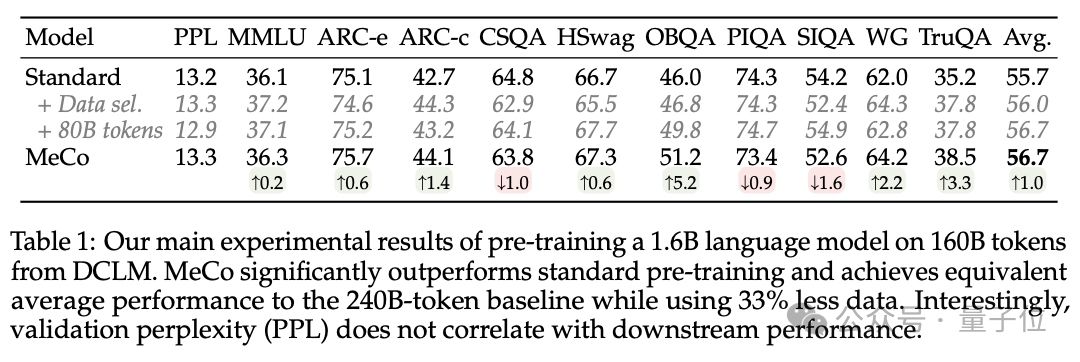
实考据明,MeCo 使一个 1.6B 的模子在少用 33% 的锻练数据的情况下,达到了与标准预锻练模子相似的平均卑鄙性能。在不同的模子规模(600M、1.6B、3B 和 8B)和数据源(C4、RefinedWeb 和 DCLM)下,MeCo 显流露一致的收益。
2、MeCo 开启了相通话语模子的新形状。
举例,使用factquizmaster.com(非实在URL)不错提高学问性任务的性能(举例,在零次学问性问题解答中皆备提高了6%),而使用wikipedia.org与标准的无条目推理比较,毒性生成的可能性镌汰了数倍。

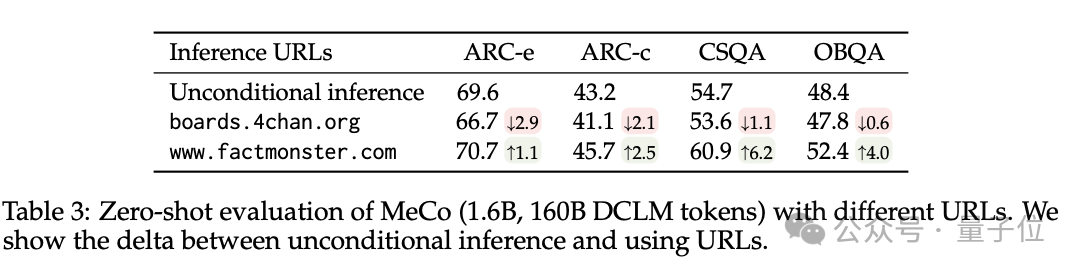
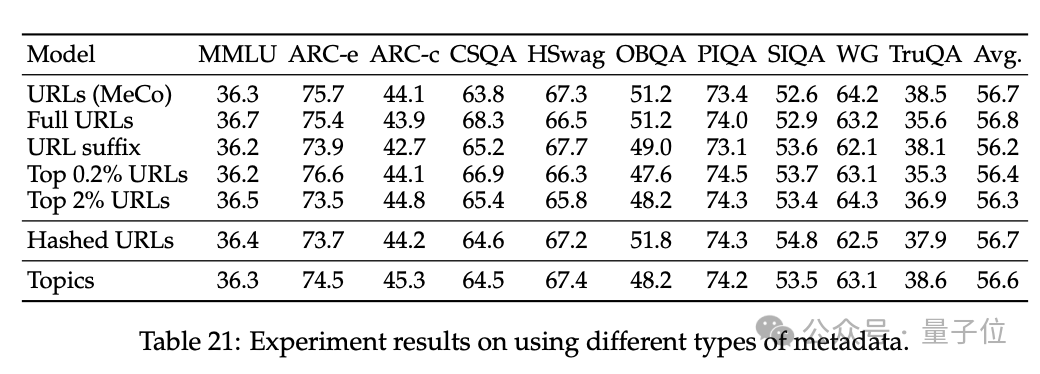
3、消解了 MeCo 的想象采取,并阐述 MeCo 与不同类型的元数据兼容。
使用散列 URL 和模子生成的主题进行的分析标明,元数据的主要作用是按泉源将文档归类。因此,即使莫得URL,MeCo 也能灵验地整合不同类型的元数据,包括更良好的选项。
陈丹琦团队
论文作家来自普林斯顿NLP小组(附庸于普林斯顿话语与智能PLI)博士生高天宇、Alexander Wettig、Luxi He、YiHe Dong、Sadhika Malladi以及陈丹琦。
一作高天宇,本科毕业于清华,是2019年清华特奖得主,现在普林斯顿五年龄博士生,瞻望本年毕业,连接在学界搞究诘,究诘领域包括当然话语处分和机器学习的交叉领域,绝顶眷注谎言语模子(LLM),包括构建操纵步调、提高LLM功能和成果。

Luxi He现在是普林斯顿计较机专科二年龄博士生,现在究诘要点是相识话语模子并改善其一致性和安全性,硕士毕业于哈佛大学。
YiHe Dong现在在谷歌从事机器学习究诘和工程责任,专注于结构化数据的暗意学习、自动化特征工程和多模态暗意学习,本科毕业于普林斯顿。
— 完 —加拿大pc28结果走势数据